これまで触れてこなかった文字列の仕様について、軽く説明していきます。 何故今更文字列なのか…それは、配列とクラスという考え方が必要になるからです。
今回は、これまで何気なく使ってきた文字列の秘密に迫ります。(多少大袈裟ですね。)
文字列の謎
普通、他言語では文字列を変数に代入する事は出来ません。 詳しい説明は省きますが、システム設計上や、文字の特徴の問題に起因しています。 よって、文字を配列化して文字列を表現します。
str = ["あ","い","う"];
配列は要素数(箱の数)に上限は(基本的に)ありません。 ですから、文字の数に制限が無い…つまり、可変長の文字列が実現できるのです。
TJSでは、これまでデータ型を考えずにあらゆるデータを変数に代入出来ました。 文字列も何も考えずに代入が出来ましたが、内部的にはこのような特殊配列構造になっているのです。
文字列は配列のようなものであり、クラスのようなものです。 まずはこの点を記憶しておいてください。
文字コード
リファレンスを呼んでいると、所々で文字コードという名前が出てきます。 コンピュータに詳しくない方からすると、何の事か分からないかもしれません。 例えば、次のような記述がありますね。
文字コードはワイド文字 ( 通常は UNICODE ) を扱いますが、16bitのワイド文字か 32bitのワイド文字かは...
※リファレンス内、データ型の項より抜粋
小難しい話は抜きにして、TJSで文字をどのように扱っているかを簡潔に説明します。
上記の抜粋文には文字コードはUNICODEを扱うと書かれています。 文字コードというのは、簡単に言えば文字を数字で表現したもので、 TJSはUNICODEという表現方法を用いて、文字を認識しているという事になりますね。
文字コードの確認方法は次のようにします。(MicroSoft(c) IMEを例に挙げます。)
- 文字を入力可能な領域(例えばブラウザのアドレスバー内)をクリックします。
- タスクバーにあるIME内「IMEパッド」をクリックし、「文字一覧」をクリックします
開いたダイアログに表示された文字にカーソルを合わせて、文字コードを確認して見ましょう。 見る点は Unicode と書かれた部分です。
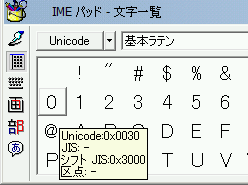
この画像を見る限り、文字の0には 0x0030 という数字が割り当てられています。 つまり 0x0030 は『0』の文字コードを指しているのです。(この0は半角です。) 同様に1,2,3は0x0031、0x0032、0x0033...と続いている事を確認できます。
コンピュータ上で「あいうえお」と表示しているように見えて、 内部的には、このような複雑な数字の並びで文字を表示させている、というわけですね。
文字化けの秘密
インターネットで、文字が暗号のように表示されて、全く読めないサイトに出会った事は無いですか? そして、エンコードでシフトJISやEUCに変更すると解消された事…ありますよね。 これも、実は文字コードが関係しているのです。
文字コードは、UNICODEやEUCといった表現方法によって、文字と対応する数字が全く異なるのです。 記号の¥はシフトJISでは0xffe5と書かれていますし、Unicodeでは0x818fとなっています。
つまり、文字コードは何もTJSの仕様ではなく、コンピュータ(OS)上の取り決めであり、 単にどの表現方法を用いているか、という違いに過ぎないのです。
(厳密には、文字コードは複雑な概念がからんでいますし、詳しい方から怒られそうですが、 今回は深く追求せず、コンピュータは文字を数字で扱っているという点だけを説明するに留めます。)